19 Shrinkage and Regularized Regression
Prerequisites
library("rstan")
library("rstanarm")
# rstanarm automatically sets the theme
theme_set(theme_gray())
library("bayz")
library("tidyverse")
library("broom")
library("glmnet")
library("recipes")19.1 Introduction
In this chapter, we will discuss shrinkage and regularization in regression problems. These methods are useful for improving prediction, estimating regression models with many variables, and as an alternative to model selection methods.
Shrinkage estimation deliberately increases the bias of the model in order to reduce variance and improve overall model performance, often at the cost of individual estimates (Efron and Hastie 2016, 91). Maximum likelihood estimation will produce asymptotically unbiased (consistent) estimates, given certain regularity conditions. However, the bias-variance tradeoff implies that generalization error can be decreased with a non-zero amount of bias. By adding bias to the model, shrinkage estimators provide a means to adjust the bias-variance in the model in order to achieve lower generalization error.
In the Bayesian estimation, shrinkage occurs as a result of hierarchical models. When parameters are modeled as exchangeable and given a proper prior, it induces some amount of shrinkage. Likewise, Bayesian models with non- or weakly-informative priors will produce similar to the MLE. But stronger priors can produce estimate much different estimtes than MLE.
Regularization describes any method that reduces variability in high dimensional estimation or prediction problems to allow estimation of unidentified or ill-posed questions or decrease overfitting or generalization error (Efron and Hastie 2016). Regularization can be thought of as the why and what of these methods, and shrinkage can be thought of as the how.
A particularly important case of shrinkage is sparse shrinkage. Sparse shrinkage estimators produce solutions that can be sparse, containing zeros. In the optimizatization case, shrinkage The most well known of these is the lasso.
For all of these examples we will be considering a linear regression with normal errors, \[ y_i \sim \dnorm(\alpha + x'_i \beta, \sigma) \] where there are \(i = 1, \dots, n\) observations, \(x_i\) is a \(k \times 1\) vector of predictors, \(\alpha\) and \(\sigma\) are scalars, and \(beta\) is a \(k \times 1\) vector of predictors.
19.2 Shrinkage Estimators
19.2.1 Penalized Maximum Likelihood Regression
OLS finds the \(\beta\) that minimize the in-sample sum of squared errors, \[ \hat{\beta}_{\text{OLS}} = \arg\min_{\beta} \sum_{i = 1}^n (\vec{x}_i\T \vec{\beta} - y_i)^2 \]
Penalized regressions add a penalty term increasing in the magnitude of \(\beta\) to the minimization function. \[ \hat{\beta}_{\text{penalized}} = \argmin_{\beta} \sum_{i = 1}^n (\vec{x}_i\T \vec{\beta} - y_i)^2 + \underbrace{f(\beta)}_{\text{shrinkage penalty}}, \] where \(f\) is some sort of penalty function on \(\beta\) that penalizes larger (in magnitude) values of \(\beta\).
Penalized regression purposefully introduces bias into the regression in order to reduce variance and improve out-of-sample prediction. The penalty term, when chosen by cross-validation or an approximation thereof, allows for trading off bias and variance.
Different penalized regression methods use different choices of \(f(\beta)\). The two most commonly penalty functions are Ridge and Lasso.
Ridge regression uses the following penalty (Hoerl and Kennard 1970): \[ \hat{\beta}_{\text{ridge}} = \arg\min_{\beta} \underbrace{\sum_{i = 1}^n (\vec{x}_i\T \vec{\beta} - y_i)^2}_{\text{RSS}} + \underbrace{\lambda}_{\text{tuning parameter}} \underbrace{\sum_{k} \beta_k^2}_{\ell_2 \text{ norm}^2} \] The \(\ell_2\) norm of \(\beta\) is, \[ ||\beta||_{2} = \sqrt{\sum_{k = 1}^K \beta_k^2} . \]
The ridge regression coefficients are smaller in magnitude than the OLS coefficients, \(|\hat{\beta}_{ridge}| < |\hat{\beta}_{OLS}|\). However, this bias in the coefficients can be offset by a lower variance, better MSE, and better out-of-sample performance than the OLS estimates.
Unlike many other penalized regression estimators, ridge regression has a close-form solution. The expected value and variance-covariance matrix of the ridge regression coefficients is, \[ \begin{aligned}[t] \E[\hat{\beta}_{\text{ridge}}] &= W X' y \\ \Var[\hat{\beta}_{\text{ridge}}] &= \sigma^2 W' X' X W , \\ W &= (X' X + \lambda I)^{-1} . \end{aligned} \] The solution is similar to the least squares solution, with the addition of the \(\lambda I\) term to \(X' X\).
As \(\lambda \to 0\), \(\hat{\beta}_{\text{ridge}} \to \hat{\beta}_{\text{OLS}}\).
As \(\lambda \to \infty\), \(\hat{\beta}_{\text{ridge}} \to 0\).
The bias of ridge regression is, \[ \mathrm{Bias}(\hat{\beta}_{\text{ridge}}) = -\lambda W \beta \] Thus, \(\mathrm{Bias}(\hat{\beta}_{\text{ridge}})\) is decreasing in the shrinkage factor \(\lambda\). The bias of ridge regression is non-zero, \(\mathrm{Bias}(\hat{\beta}_{\text{ridge}}) \neq 0\) when \(\lamba > 0\). When \(\lambda \to 0\), then \(\mathrm{Bias}(\hat{\beta}_{\text{ridge}}) \to 0\).
Additionally, \[ \Var(\hat{\beta}_{\text{ridge}}) < \Var(\hat{\beta}_{\text{OLS}}) \] and \(\Var(\hat{\beta}_{\text{ridge}})\) is decreasing as \(\lambda \to \infty\).
The most important result with respect to ridge regression is that there always exists a \(\lambda\) such that, \[ MSE(\hat{\beta}_{\text{ridge}}(\lambda)) < MSE(\hat{\beta}_{\text{OLS}}) . \]
The complexity of the model is the degrees of freedom. In OLS, the degrees of freedom is the trace of the hat matrix, \[ \tr(H_{\text{OLS}}) = k \] where \[ H_{\text{OLS}} = (X' X)^{-1} X' . \]
In ridge regression, the degrees of freedom is the trace of the analagous hat matrix, \[ df_{\text{ridge}} = \tr(H_{\text{ridge}}) = \sum \frac{\lambda_i}{\lambda_i + \lambda} \] where \[ H_{\text{ridge}} = X W X' , \] and \(\lambda_i\) are the eigenvalues of \(X' X\). When \(\lambda \to 0\), then \(df = k\), and when \(\lambda \to \infty\), then \(df = 0\). As expected, as the penalty factor increases the model complexity decreases.
Some other implications:
\(\hat{\vec{\beta}}\) exists even if \(\hat{\vec{\beta}}_{\text{OLS}}\) (\((\mat{X}\T\mat{X})^{-1}\)), i.e. cases of \(n > p\) and collinearity, does not exist.
If \(\mat{X}\) is orthogonal (mean 0, unit variance, zero correlation), \(\mat{X}\T \mat{X} = n \mat{I}_p\) then \[ \hat{\vec{\beta}}_{\text{ridge}} = \frac{n}{n + \lambda} \hat{\vec{\beta}}_{\text{ols}} \] meaning, \[ |\hat{\vec{\beta}}_{\text{ols}}| > |\hat{\vec{\beta}}_{\text{ridge}}| \geq 0 \]
Ridge does not produce sparse estimates, since \((n / (n + \lambda)) \vec{\vec{\beta}}_{ols} = 0\) iff \(\vec{\vec{\beta}}_{ols} = 0\)
If \(\lambda = 0\), then the ridge coefficients are the same as the OLS coefficients, \(\lambda \to 0 \Rightarrow \hat{beta}_{\text{ridge}} \to \hat{beta}_{OLS}\)
As \(\lambda\) increases the coefficients are shrunk to 0, \(\lambda \to \infty \Rightarrow \hat{\beta}_{\text{ridge}} = 0\).
19.2.2 Bayesian Shrinkage
As shown in the hierarchical chapter, modeling parameters hierarchically can shrink them. Consider the regression model, \[ y_i \sim \dnorm(\alpha + x'_i \beta_k) . \] In the case of shrinkage in regularization, a hierarchical prior is applied to the regression coefficients \(\beta\).
The intercept, \(\alpha\), is generally not shrunk. In all these cases, it can be given a weakly-informative prior such as, \[ y_i \sim \dnorm(0, 10) . \]
19.2.2.1 Normal Priors
Unlike the weakly informative priors, the prior distributions all share a scale parameter \(\tau\). \[ \beta_k | \tau \sim \dnorm(0, \tau) \]
We need to assign a prior to \(\tau\). Often this is assigned an “uninformative” gamma or inverse-gamma prior because it has conjugacy properties. Analagous to later priors and current advice about scale parameter choices in Stan, a Student-t distribution with location 0, and a user-specified degrees of freedom \(d_\tau\) and \(s_\tau\) is reasonable, \[ \tau \sim \dt(d_\tau, 0, s_\tau) . \]
19.2.2.1.1 Relationship to Ridge Regression
For a given \(\lamba\), the ridge regression estimator is a MAP estimator of the model, \[ \begin{aligned}[t] y_i &\sim \dnorm(\alpha + x' \beta, \sigma) \\ \beta_k &\sim \dnorm(0, (2 \lambda)^{-1/2} ) . \end{aligned} \]
Recall that although OLS does not require normal errors, the OLS coefficients are equivalent to the MLE of a probability model with normal errors, \[ \begin{aligned} \hat{\beta}_{MLE} &= \arg \max_{\beta} \dnorm(y | x \beta, \sigma) \\ & = \arg \max_{\beta} {(2 \pi \sigma^2)}^{n / 2} \prod_{i = 1}^{n} \exp\left(-\frac{(y_i - x_i' \beta)^2}{2 \sigma^2}\right) \\ &= \arg \max_{\beta} \frac{n}{2} (\log 2 + \log \pi) + n \log \sigma + \sum_{i = 1}^{n} \left( -\frac{(y_i - x_i' \beta)^2}{2 \sigma^2} \right) \\ & = \arg \max_{\beta} \sum_{i = 1}^{n} - (y_i - x'_i \beta)^2 \\ &= \arg \min_{\beta} \sum_{i = 1} (y_i - x'_i \beta)^2 \\ &= \hat{\beta}_{OLS} \end{aligned} \] Likewise the shrinkage prior can be represented as a normal distribution with mean 0 and scale \(1 / \lambda\), since the \(\beta\) that maximize the probability of that, minimize the \(\ell_2\) norm of \(\beta\), \[ \begin{aligned} \arg \max_{\beta} \dnorm(\beta | 0, \tau) &= \arg \max_{\beta} {(2 \pi \sigma^2)}^{K / 2} \prod_{k = 1}^{K} \exp\left(- \frac{(0 - \beta_k)^2}{2 \tau^2} \right) \\ &= \arg \max_{\beta} \sum_{k = 1}^{K} \left(-\frac{\beta_k^2}{2 \tau^2}\right) \\ &= \arg \min_{\beta} \frac{1}{2 \tau^2} \sum_{k = 1}^K \beta_k^2 , \end{aligned} \] where \(\tau^2 = 1 / 2 \lambda\).
19.2.2.2 Student-t Distribution
We can generalize the previous case and use Student-t distributions as a prior for the coefficients. The Cauchy distribution is a special case of the Student t distribution where the degrees of freedom is one.
The prior distribution for each coefficient \(\beta_k\) is a Student-t distribution with degrees of freedom \(\nu\), location 0, and scale \(\tau\), \[ \beta_k | \tau \sim \dt(\nu, 0, \tau) . \] Like many priors that have been proposed and used for coefficient shrinkage, this can be represented as a local-global scale-mixture of normal distributions. \[ \begin{aligned} \beta_k | \tau, \lambda &\sim \dnorm(0, \tau \lambda_k) \\ \lambda_k^{-2} &\sim \dgamma(\nu/2, \nu/2) \end{aligned} \]
The degrees of freedom parameter \(\nu\) can be fixed to a particular value or estimated. If fixed, then common values are 1 for a Cauchy distribution, 2 to ensure that there is a finite mean, 3 to ensure that there is a finite variance, and 4 ensure that there is a finite kurtosis.
If the degrees of freedom is not specified, then use the prior, \[ \nu \sim \dgamma(2, 0.1) \] Additionally, it may be useful to truncate the values of \(\nu\) to be greater than 2 to ensure a finite variance of the Student t distribution.
The following figure plots the probability density functions for normal, Cauchy, and Student-t (\(df = 4\)) distributions. Relative to a normal distribution, Student-t distributions will place more prior probability mass closer to zero, and also more mass that the distribution can be far large.
tibble(x = seq(-5, 5, length.out = 100),
`Normal` = dnorm(x),
`Cauchy` = dcauchy(x),
`Student-t (df = 4)` = dt(x, 4)) %>%
gather(Distribution, Density, -x) %>%
ggplot(aes(x = x, y = Density, colour = Distribution)) +
geom_line() +
xlab(expression(beta)) +
ylab(expression(paste("p", "(", beta, ")")))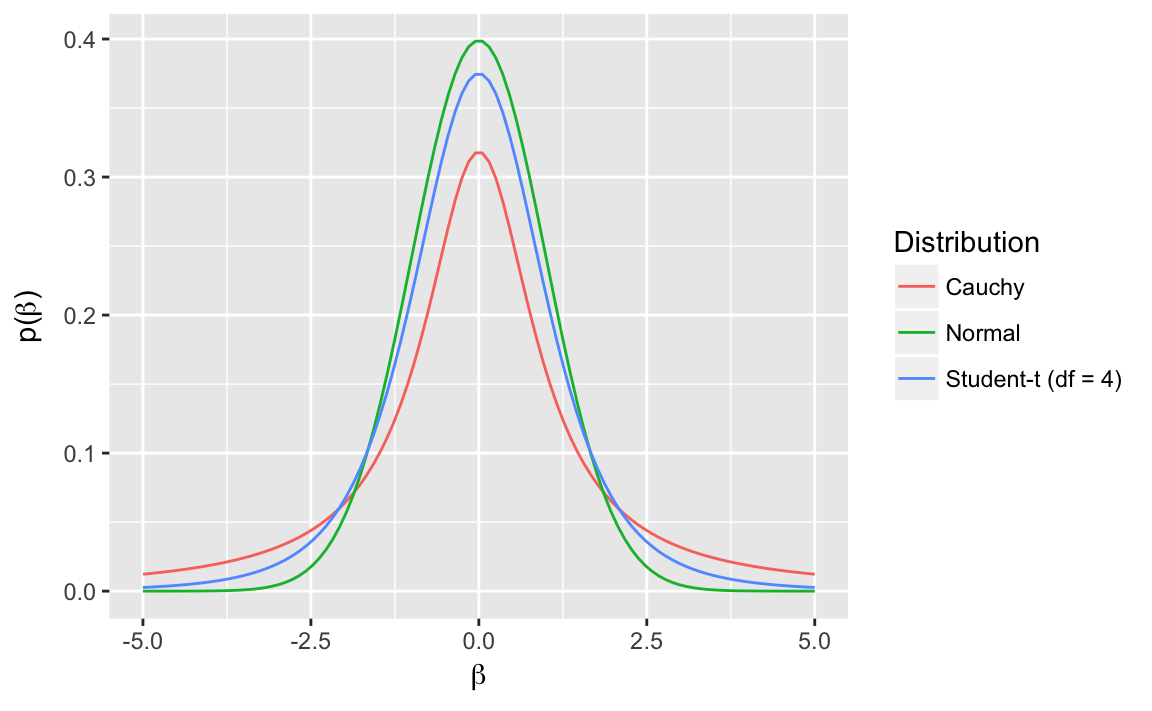
Note that, the use of a Student \(t\) distribtion in the regression here is different than the use of the Student-t distribution for robustness. In the robustness case, \(y_i\) is distributed Student-t, \[ y_i \sim \dt(\nu_y, \alpha + x_i' \beta, \sigma), \] or equivalently, the errors, \(\epsilon_i\), are distributed Student-t, \[ y_i = \alpha + x'_i \beta + \epsilon_i \\ \epsilon_i \sim \dt(\nu, 0, \sigma) \]
In regularized regression with Student-t priors, the \(\beta\) are distributed Student-t. These models could be combined, with a \(\epsilon_i\) distributed Student-t and \(\beta\) given Student-t priors, for a regularized robust regression.
19.3 Sparse Shrinkage
A sparse shrinkage estimator is one that produces point estimates exactly equal to zero (in MAP), or posterior distributions where for some parameters, the probability density mass concentrates around zero (in full Bayes).
Ridge regression and the prior distributions covered thus far are not sparse shrinkage estimators.
Many of the proofs and results regarding the performance of these methods are for the case that the true parameters are sparse, usually defined as \[ n \to \infty \Rightarrow k / n \to 0 , \] where \(k\) is the true number of non-zero parameters, and \(n\) is the number of observations.
Of sparse shrinkage estimators for regression coefficients, the most popular optimization MAPS
There are two main approaches to sparsity in Bayesian statistics [CarvalhoPolsonScott2009a]:
- discrete mixtures that place a point mass at \(\beta_k = 0\) (Beauchamp 1988, George and McCulloch 1993). THis is called a spike-and-slab prior.
- shrinkage solution which uses an absolutely continuous prior that places a large mass of its density near zero. The horseshoe prior is an example of this. Using Laplace (double exponential) priors, although analagous to the the lasso, is not an example.
19.3.1 Penalized Likelihood
The lasso (Least Absolute Shrinkage and Selection Operator) uses an \(\ell_1\) norm of \(\beta\) as a penalty (Tibshirani 1996), \[ \hat{\beta}_{\text{lasso}} = \arg\min_{\beta} \frac{1}{2 \sigma} \sum_{i = 1}^n (\vec{x}_i\T \vec{\beta} - y_i)^2 + \lambda \sum_{k} |\beta_k| \] where \(\lambda \geq 0\) is a tuning or shrinkage parameter chosen by cross-validation or a plug-in statistic.
The \(\ell_1\) norm of \(\beta\) is the sum of the absolute values of its elements, \[ ||\beta||_{1} = \sum_{k = 1}^K |\beta_k| . \]
Properties:
Unlike ridge regression, it sets some coefficients exactly to 0, producing sparse solutions.
If variables are perfectly correlated, there is no unique solution (unlike the ridge regression).
Used as the best convex approximation of the “best subset selection” regression problem, which finds the number of nonzero entries in a vector.
Unlike ridge regression, there is no closed-form solution. Since \(|\beta_k|\) does not have a derivative, it was a more difficult iterative problem than many other regression functions. However, now there are several algorithms to estimate it.
19.3.2 Bayesian Sparse Shrinkage Models
19.3.2.1 Mixture Models
This is a “gold standard” for sparse Bayesian estimation. It directly represents sparsity with a point mass on \(\beta_k\). The prior is a two-component mixture of normal distributions \[ \begin{aligned}[t] \beta_k | \lambda_k, c, \epsilon &\sim \lambda_k N(0, c^2), + (1 - \lambda_j) N(0, \epsilon^2) \\ \lambda_k &\sim \dbern(\pi), \end{aligned} \] for \(k = 1, \dots, K\), and \(\epsilon << c\). The indicator variable \(\lambda_{k} \in \{0, 1}\) denotes whether \(\beta_j\) is close to zero; \(\lambda_k = 0\) means that the coefficient came from the spike, and \(\lambda_k = 1\) means that the coefficient came from the slab. The value of \(\epsilon\) can be either 0, implying a delta spike at 0, or \(\epsilon > 0\), but small. The values of \(c\) and \(\pi\) need to be chosen or assigned priors.
If \(\epsilon = 0\), then \[ \begin{aligned} \beta_k | \lambda_k, c &\sim \dnorm(0, c^2 \lambda^2_k), \\ \lambda_k &\sim \dbern(\pi) \end{aligned} \] The shrinkage parameter only takes two values, \[ \kappa = \begin{cases} 1 & \lambda_k = 0 \\ \frac{1}{1 + n \sigma^{-2} s^2_k c^2} & \lambda_k = 1 \end{cases} \] As \(c \to \infty\), then \(\kappa = \{0, 1}\), with shrinkage occurring either completely or not at all.
In the case of the linear regression, an alternative to BMA is to use a spike-and-slab prior (Mitchell and Beauchamp 1988, @GeorgeMcCulloch1993a, @IshwaranRao2005a), which is a prior that is a discrete mixture of a point mass at 0 and a non-informative distribution.
The posterior distribution of \(w\) is the probability that \(\beta_k \neq 0\), and the conditional posterior distribution \(p(\beta_k | y, w = 1)\) is the distribution of \(\beta_k\) given that \(\beta_k \neq 0\).
See the R package spikeslab and he accompanying article (Ishwaran, Kogalur, and Rao 2010) for an implementation and review of spike-and-slab regressions.
19.3.2.2 Bayesian Lasso
Similarly, the \(\beta\) that minimize the \(\ell_1\) norm also maximize the probability of random variables iid from the Laplace distribution, \(\dlaplace(\beta_k | 0, 1 / \lambda)\). \[ \begin{aligned} \arg \max_{\beta} \dlaplace(\beta | 0, 1 / \lambda) &= \arg \max_{\beta} \left(\frac{\lambda}{2}\right)^{K} \prod_{k = 1}^{K} \exp\left(- \lambda |0 - \beta_k)| \right) \\ &= \arg \max_{\beta} \sum_{k = 1}^{K} - \lambda |\beta_k| \\ &= \arg \min_{\beta} \lambda \sum_{k = 1}^K |\beta_k| . \end{aligned} \] Thus lasso regression can be thought of as a MAP estimator of the model, \[ \begin{aligned}[t] y_i &\sim \dnorm(\alpha + x' \beta, \sigma) , \\ \beta_k &\sim \dlaplace(0, 1 / \lambda) . \end{aligned} \] The only difference in the lasso is the penalty term, which uses an absolute value penalty for \(\beta_k\). That term corresponds to a sum of log densities of i.i.d. double exponential (Laplace) distributions. The double exponential distribution density is similar to a normal distribution, \[ \log p(y | \mu, \sigma) \propto - \frac{|y - \mu|}{\sigma} \] So the LASSO penalty is equivalent to the log density of a double exponential distribution with location \(0\), and scale \(1 / \lambda\). \[ \beta_k \sim \dlaplace(0, \tau) \]
19.3.2.3 Horseshore Prior
The Horseshoe prior is defined solely in terms of a global-local mixture.
\[
\begin{aligned}
\beta_k | \tau, \lambda &\sim \dnorm(0, \tau \lambda_k) \\
\lambda_k &\sim \dhalfcauchy(0, 1) \\
\tau &\sim \dhalfcauchy(0, \tau_0)
\end{aligned}
\]
The heavy-tailed Cauchy prior on \(\lambda_k\) allows individual coefficients to offset and global shrinkage, \(\tau\), and take large values with little shrinkage.
However, the horseshoe prior has computational issues.
The heavy-tails can produce a posterior which does not sufficiently identify large slope coefficients, making it hard to sample.
In HMC-NUTS, these issues will reveal themselves as divergences and often require increase the value of adapt or increasing the value of the treedepth.
The hierarchical shrinkage prior replaces the half-Cauchy prior on \(\lambda_k\) with a half-Student-t distribution with degrees of freedom \(\nu\). \[ \lambda_k \sim \dhalft(\nu, 0, 1) \] The \(\nu\) parameter is generally not estimated and fixed to a low value, with \(\nu = 4\) being suggested. The problem with estimating the horseshoe prior is that the wide tails of the Cauchy prior produced a posterior distribution with problematic geometry that was hard to sample. Increasing the degrees of freedom helped to regularize the posterior. The downside of this method is that by increasing the degrees of freedom of the Student-t distribution it would also shrink large parameters, which the horseshoe prior was designed to avoid.
The regularized horseshoe prior (or Finnish horseshoe prior) is defined as
\[
\begin{aligned}
\beta_k | \tau, \lambda &\sim \dnorm(0, \tau \tilde{\lambda}_k) \\
\tilde{\lambda}_k &= \frac{c \lambda}{\sqrt{c^2 + \tau \lambda^2}} \\
\lambda_k &\sim \dhalfcauchy(1) \\
c^2 &\sim \invgamma(d_{\text{slab}} / 2, d_{\text{slab}} s_{\text{slab}}^2 / 2) \\
\tau &\sim \dhalfcauchy(0, \tau_0^2)
\end{aligned}
\]
Where \(d_{\text{slab}}\) is the degrees of freedom for the slab, and \(s_{\text{slab}}\) is the scale of the slab.
For defaults rstanarm uses \(d_{\text{slab}} = 4\) and \(s_{\text{slab}} = 2.5\).
Like using a Student-t distribution, this regularizes the posterior distribution of a Horseshoe prior.
However, it is less problematic than using the Student-t distribution because it shrinks large coefficients less.
The value of \(\tau\) and the choice of its hyper-parameter has a big influence on the sparsity of the coefficients.
19.4
Piironen and Vehtari (2017) treat the prior on \(\tau\) as the implied prior on the number of effective parameters. The shrinkage can be understood as its influence on the number of effective parameters, \(m_{eff}\), \[ m_{\text{eff}} = \sum_{j = 1}^K (1 - \kappa_j) . \] This is a measure of effective model size.
Piironen and Vehtari (2017) show that for a given \(n\) (data standard deviation), \(\tau\), \(\lambda_k\), and \(\sigma\), the and variance of \(m_{eff}\) \[ \begin{aligned}[t] \E[m_{eff} | \tau, \sigma] &= \frac{\sigma^{-1} \tau \sqrt{n}}{1 + \sigma^{-1} \tau \sqrt{n}} K , \\ \Var[m_{eff} | \tau, \sigma] &= \frac{\sigma^{-1} \tau \sqrt{n}}{2 (1 + \sigma^{-1} \tau \sqrt{n})2} K . \end{aligned} \]
Given a prior guess about the sparsity \(\beta\), a prior should be chosen such that it places mass near that guess. Let \(k_0 \in [0, K]\) be the expected number of non-zero elements of \(\beta\), then choose \(\tau_0\) such that \[ \tau_0 = \frac{k_0}{K - k_0}\frac{\sigma}{\sqrt{n}} \]
This prior depends on the expected sparsity of the solution, which depends on the problem. PiironenVehtari2017a provide no guidence on how to select \(p_0\). Perhaps a simpler model, e.g. lasso could be used to estimate \(p_0\).
- Datta and Ghosh (2013) warn against empirical Bayes estimators of \(\tau\) for the horseshoe prior as it can collapse to 0.
- Scott and Berger (2010) consider marginal maximum likelihood estimates of \(\tau\). –>
- Pas, Kleijn, and Vaart (2014) suggest that an empirical Bayes estimator truncated below at \(1 / n\).
19.4.1 Shrinkage Factor
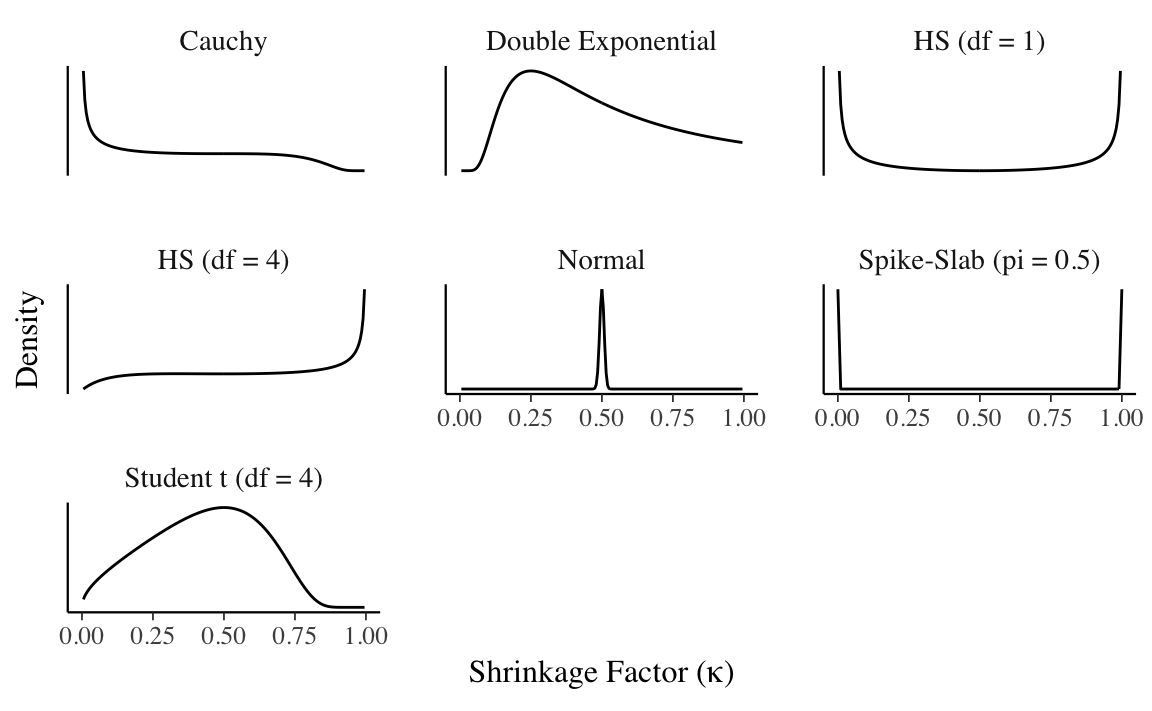
Suppose that \(X\) is a \(n \times K\) matrix of predictors, and \(y\) is a \(n \times 1\) vector of outcomes. The conditional posterior for \(\beta\) given \((X, y)\) is \[ \begin{aligned}[t] p(\beta | \Lambda, \tau, \sigma^2, D) &= \dnorm(\beta | \bar{\beta}, \Sigma), \\ \bar{\beta} &= \tau^2 \Lambda (\tau^2 \Lambda + \sigma^2 (X'X)^{-1})^{-1} \hat{\beta}, \\ \Sigma &= (\tau^{-2} \Lambda^{-1} + \frac{1}{\sigma^{2}} X'X)^{-1}, \\ \Lambda &= \diag(\lambda_1^{2}, \dots, \lambda^{2}_D), \\ \hat{\beta} &= (X'X)^{-1} X'y . \end{aligned} \] If the predictors are uncorrelated with zero mean and variances \(\Var(x_k) = s_k^2\), then \[ X'X \approx n \diag(s_1^2, \dots, s^2_K) , \] and we can use the approximations, \[ \bar{\beta}_k = (1 - \kappa_k) \hat{\beta}_k, \\ \kappa_k = \frac{1}{1 + n \sigma^{-2} \tau^2 s_k^2 \lambda_k^2} . \] The value \(\kappa_k\) is called the shrinkage factor for coefficient \(\beta_k\). When \(\kappa_k = 0\), then there is no shrinkage and the posterior coefficient is the same as the MLE solution, \(\bar{\beta} = \hat{\beta}\). When \(\kappa_k = 1\), then there is complete shrinkage and the posterior coefficient is zero, \(\bar{\beta} = 0\). It also follows that \(\bar{\beta} \to 0\) as \(\tau \to 0\), and \(\bar{\beta} \to \hat{\beta}\) as \(\tau \to \infty\).
shrinkage_factor <- function(n, sigma = 1, tau = 1, sd_x = 1, lambda = 1) {
1 / 1 + n * tau ^ 2 * sd_x ^ 2 * lambda ^ 2 / sigma ^ 2
}19.4.2 Prior on the Global Scale
The value of \(\tau\) and the choice of its hyper-parameter has a big influence on the sparsity of the coefficients. However, there are varying suggestions for how to set this. (Carvalho, Polson, and Scott 2009, @PolsonScott2011a, @PasKleijnVaart2014a).
Shrinkage can be understood as its influence on the number of effective parameters, \(m_{eff}\) (Piironen and Vehtari 2016), \[ m_{\text{eff}} = \sum_{j = 1}^K (1 - \kappa_j) . \]
This is a measure of model complexity or model size
However, the interpretation as the “number of non-zero parameters” is less meaningful when the
The values of \(\kappa_i\) can be used for thresholding. Carvalho et al suggest a decision rule of selecting variables where \(\kappa_k > 1 / 2\).
I have not seen it described elsewhere, but the level of sparsification can be summarized by comparing the variance of \(\kappa_k\) given \(m_eff\) to the case where all \(kappa_k \in \{0, 1\}\). If all \(\kappa_k\) are zero or one, then \[ s_{\text{eff}} = \frac{\sum(\kappa_k - m_{\text{eff}} / K)^2}{(m_{\text{eff}} / K) (1 - m_{\text{eff}} / K)} \] If \(s_{eff} = 1\), then all \(\kappa_{k}\) are one or zero; if \(s_{eff} = 0\), the all \(\kappa_{k} = m_{eff} / K\) (uniform shrinkage as with a normal prior).
If the prior can be represented as a scale mixture of normal distributions, then the the mean and variance of \(m_{eff}\) are \[ \begin{aligned}[t] \E[m_{\text{eff}} | \tau, \sigma] &= \sum_{k = 1}^{K} \frac{a_k}{1 + a_k} , \\ \Var[m_{\text{eff}} | \tau, \sigma] &= \sum_{k = 1}^{K} \frac{a_k}{2 \left(1 + a_k \right)^2} . \end{aligned} \] where \(a_k = \sigma^{-1} \tau \sqrt{n} s_k\) (Piironen and Vehtari 2017).
The prior should be chosen so that the prior mass is located near \[ \tau_0 = \frac{k_0}{K - k_0}\frac{\sigma}{\sqrt{n}} . \] where \(k_0\) is a guess as to the number of non-zero coefficients. Note that the choice of \(\tau\) must scale with the observation noise \(\sigma\) and the number of observations \(n\).
Calculate the shrinkage factor \(\kappa_k\) given \(n\), \(\sigma\), \(\tau\), \(sd_x\), and \(\lambda_k\).
shrinkage_factor <- function(n, lambda = 1, tau = 1, sigma = 1, sd_x = 1) {
1 / (1 + n * tau ^ 2 * sd_x ^ 2 * lambda ^ 2 / sigma ^ 2)
}Choose $
optimal_tau <- function(k0, K, n, sigma = 1) {
k0 / (K - k0) * sigma / sqrt(n)
}19.5 Differences between Bayesian and Penalized ML
There are several differences between Bayesian approaches to shrinkage and penalized ML approaches.
The point estimates:
- ML: mode
- Bayesian: posterior mean (or median)
In Lasso
- ML: the mode produces exact zeros and sparsity
- Bayesian: posterior mean is not sparse (zero)
Choosing the shrinkage penalty:
- ML: cross-validation
- Bayesian: a prior is placed on the shrinkage penalty, and it is estimated as part of the posterior.
19.6 Examples
19.6.1 Diabetes
data("diabetes", package = "lars")The diabetes data has 442 observations (from Efron, Hastie, Johnston, Tibshirani 2003 LARS paper).
The data are provided as matrices, with x a matrix with 10 columns, y a
numeric vector with the response, and and x2 a matrix with 64 columns (x plus interactions.
The matrix x has been standardized to have zero mean and unit variance.
19.6.1.1 Penalized Regression
Before turning to full Bayesian estimation, we can produce MAP estimates for the model for the following:
- Flat priors
- Ridge regression/Normal priors/L2 penalty
- Lasso regresssion/Laplace (double exponential) priors/L1 penalty
diabetes_map_lm <- lm(y ~ x, data = diabetes)
diabetes_map_ridge <- glmnet(diabetes$x, diabetes$y, alpha = 1)
diabetes_map_lasso <- glmnet(diabetes$x, diabetes$y, alpha = 0)Note that even x was a matrix, we can use it on the right-hand-side of the formula, and the formula object knows to use the columns of it.
By default glmnet estimates the coefficients for the range of the shrinkage penalty \(\lambda\).
The sequence of values of a coefficient for values of \(\lambda\) from \(\lambda = 0\) (no shrinkage) to \(\lambda \approx \infty\) (large enough that all coefficients are zero) is called the coefficient path.
The plot method for the glmnet objects returned by glmnet() will plot coefficient paths.
Here I will extract the data using broom::tidy() and plot them with ggplot().
diabetes_coefpaths <- bind_rows(
mutate(tidy(diabetes_map_lasso), model = "Lasso (L1)"),
mutate(tidy(diabetes_map_ridge), model = "Ridge (L2)")) %>%
filter(term != "(Intercept)") diabetes_coefpaths %>%
ggplot(aes(x = -log(lambda), y = estimate, group = term)) +
geom_line() +
facet_wrap(~ model, ncol = 1, scales = "free_x") +
labs(x = expression(-log(lambda)), y = expression(beta))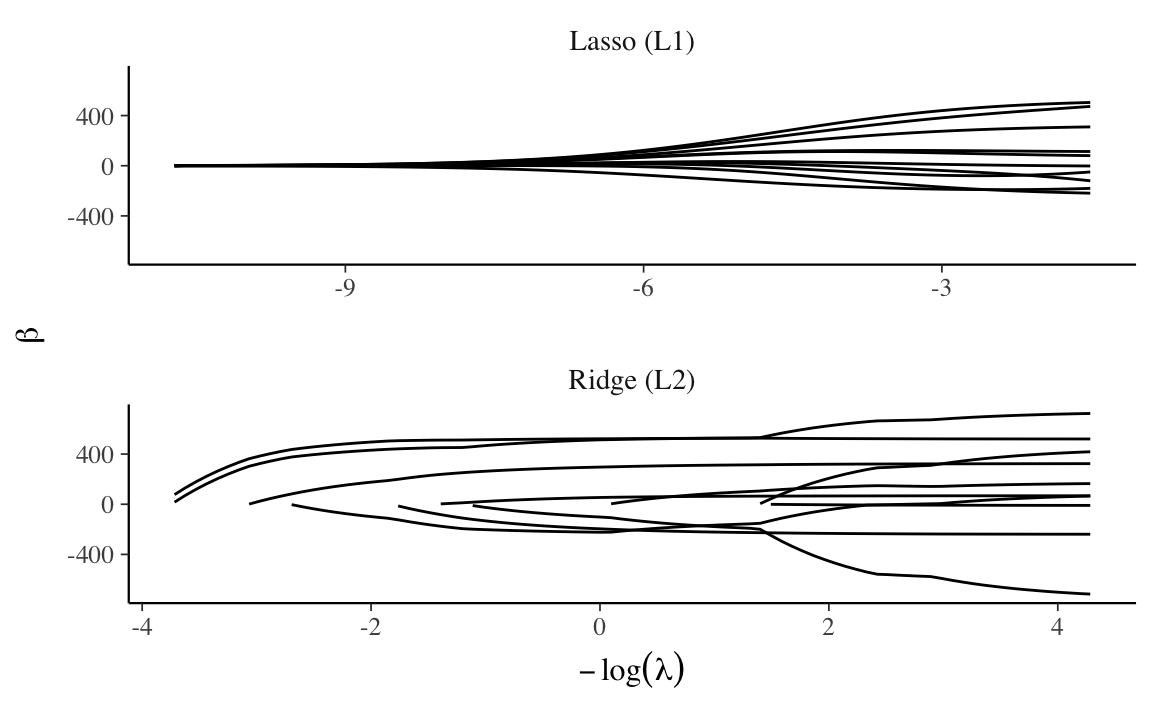 Note that the \(\lambda\) penalties are on different scales in the Lasso and ridge regession.
Nevertheless we see that the ridge regression coefficients smoothly converge towards zero as \(- \log(\lambda) \to 0\), while the lasso coefficients eventually hit zero and then are set to zero.
Note that the \(\lambda\) penalties are on different scales in the Lasso and ridge regession.
Nevertheless we see that the ridge regression coefficients smoothly converge towards zero as \(- \log(\lambda) \to 0\), while the lasso coefficients eventually hit zero and then are set to zero.
To put them on the same scale, instead of plotting the coefficient paths vs. \(\lambda\) we could instead plot it against the percent of deviance explained.
diabetes_coefpaths %>%
ggplot(aes(x = dev.ratio, y = estimate, group = term)) +
geom_line() +
facet_wrap(~ model, ncol = 1, scales = "free_x") +
labs(x = expression("% Deviance"), y = expression(beta))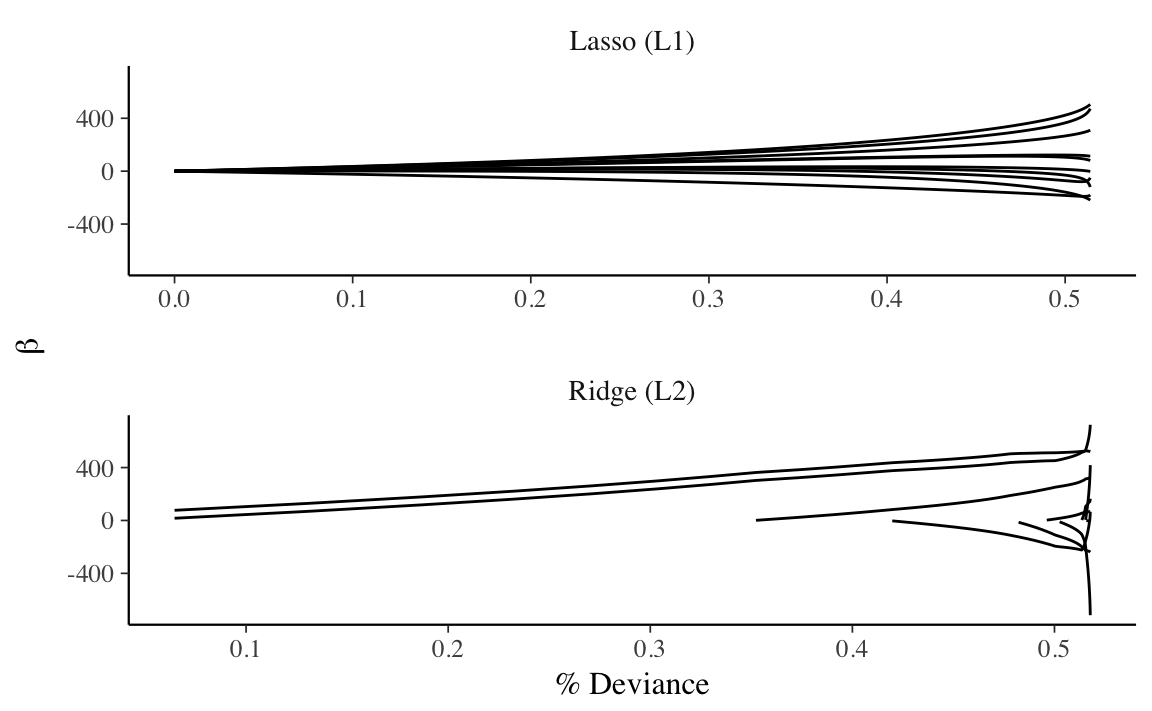
However, glmnet does not choose a value of lambda.
To choose a particular value of lambda using K-fold cross-validation, use cv.glmnet.
I will use the default value of 10 folds.
diabetes_ridge_cv <- cv.glmnet(diabetes$x, diabetes$y, alpha = 0,
nfolds = 10, parallel = TRUE)
#> Warning: executing %dopar% sequentially: no parallel backend registeredThis plots the values of \(\lambda\), the MSE (and its standard error) and the lines indicate the \(\lambda\) with the lowest MSE and the one chosen by the 1-standard deviation rule.
plot(diabetes_ridge_cv)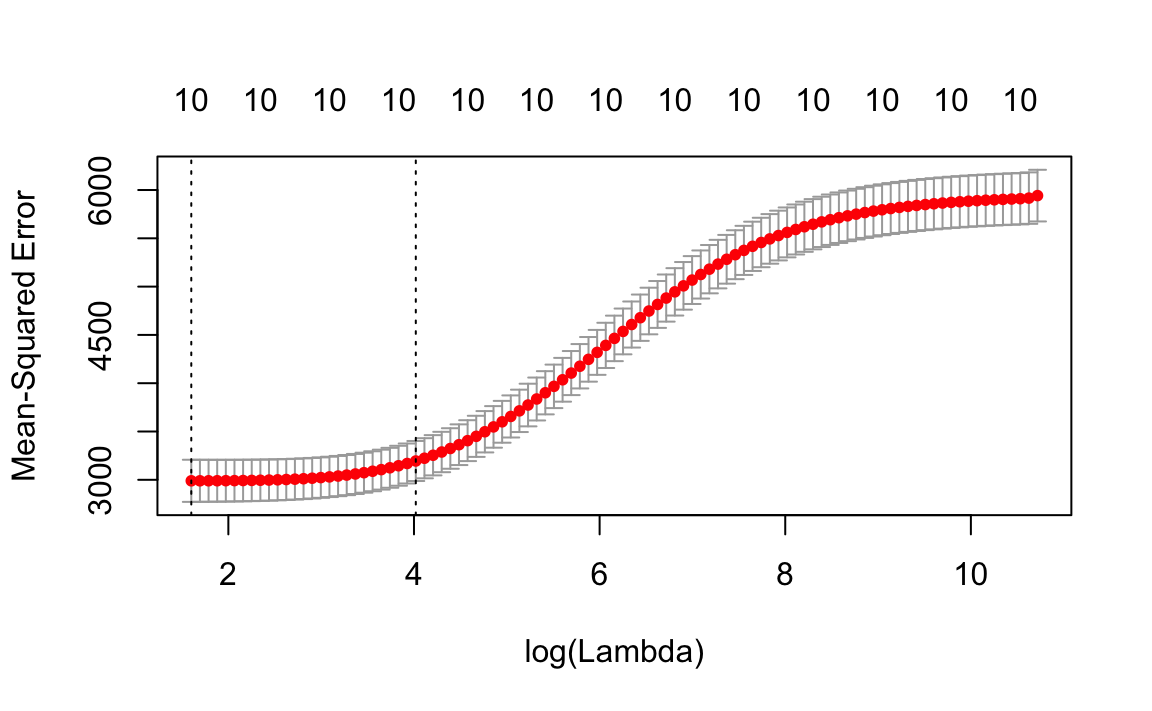
Similarly for lasso.
diabetes_lasso_cv <- cv.glmnet(diabetes$x, diabetes$y, alpha = 1,
nfolds = 10, parallel = TRUE)plot(diabetes_lasso_cv)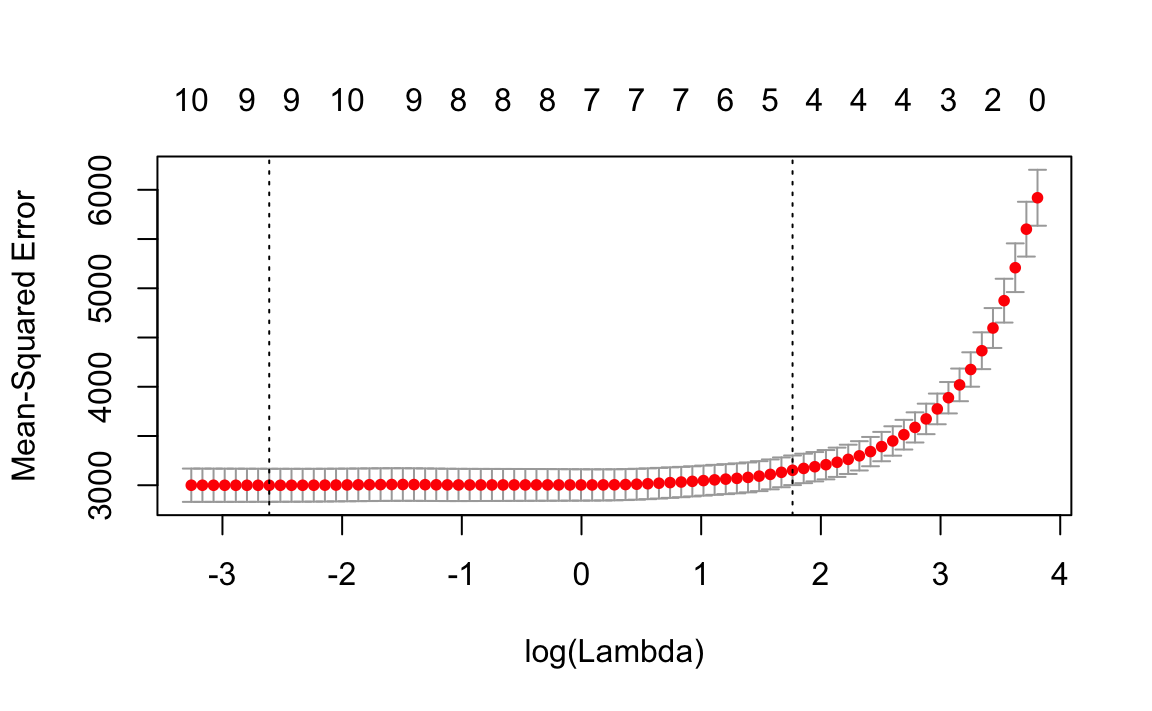
For the optimal \(\lambda\), Lasso produces the following number of non-zero coefficients:
lasso_nonzeros <- function(x, se = TRUE) {
lambdahat <- if (se) "lambda.1se" else "lambda.min"
unname(x$nzero[which(x$lambda == x[[lambdahat]])])
}
lasso_nonzeros(diabetes_lasso_cv)
#> [1] 5get_glmnet_coef <- function(x) {
lambdahat <- "lambda.1se"
coefpaths <- tidy(x[["glmnet.fit"]])
filter(coefpaths, lambda == x[[lambdahat]])
}OLS, lasso, and ridge point estimates. Coefficients are ordered in descending value of \(|\hat{\beta}_{OLS}|\).
bind_rows(
mutate(tidy(diabetes_map_lm), model = "OLS"),
mutate(get_glmnet_coef(diabetes_ridge_cv), model = "ridge"),
mutate(get_glmnet_coef(diabetes_lasso_cv), model = "lasso")) %>%
mutate(term = if_else(model %in% c("OLS"),
str_replace(term, "^x", ""), term)) %>%
select(model, term, estimate) %>%
complete(model, term, fill = list(estimate = 0)) %>%
filter(!term %in% "(Intercept)") %>%
mutate(term = fct_reorder(term, if_else(model == "OLS",
abs(estimate), NA_real_),
mean, na.rm = TRUE)) %>%
ggplot(aes(x = term, y = estimate, colour = model)) +
geom_hline(yintercept = 0, colour = "white", size = 2) +
geom_point() +
coord_flip() +
labs(y = expression(hat(beta)), x = "")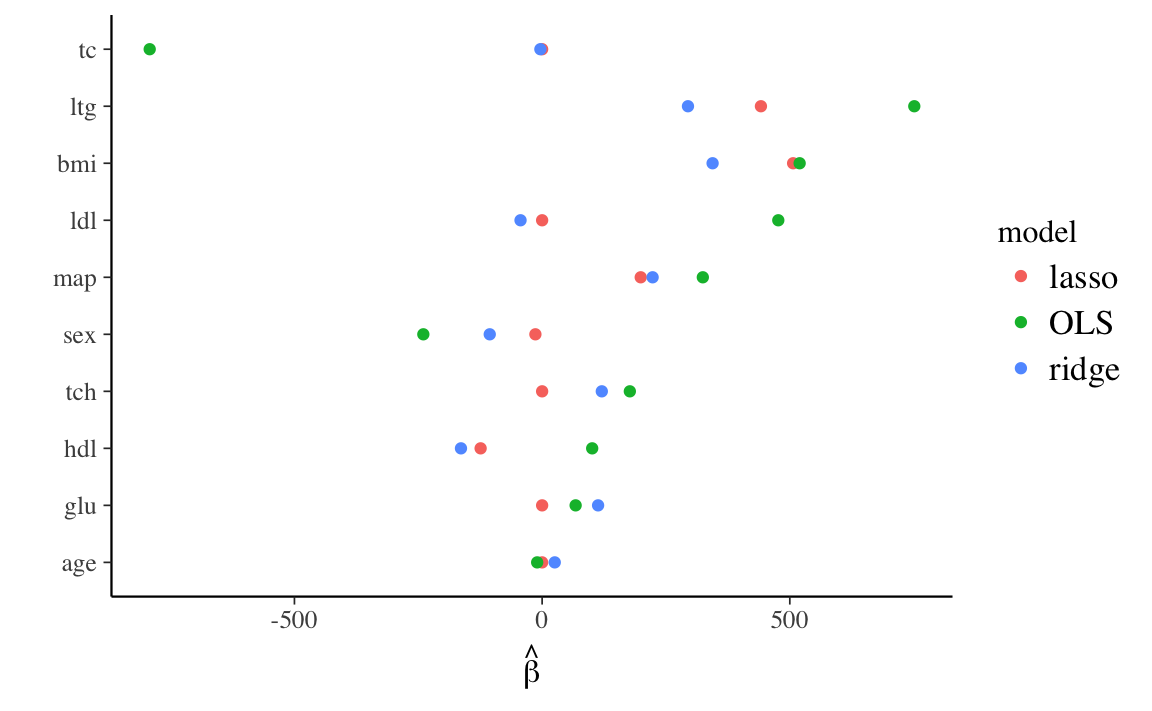 Note that while
Note that while tc has the largest OLS point estimate, both ridge and lasso
estimate it to be approximately zero.
For the hdl coefficient, the lasso and ridge estimates have a different sign than OLS
and are larger in magnitude.
19.6.1.2 Full Bayes
We can estimate this with Stan models and rstanarm. The rstanarm models are faster. However, at the moment rstanarm does not provide ridge regression. Additionally, the Stan models provided will also return the shrinkage parameters, effective number of parameters, and local scales.
19.6.1.2.1 Stan models
- Weakly informative priors
- Shrinkage with normal priors
- Shrinkage with Student t priors
- Shrinkage with Laplace priors
- Shrinkage with Horseshoe priors
model_names <- c("lm_normal_1",
"lm_shrinkage_normal_1",
"lm_shrinkage_student_t_1",
"lm_shrinkage_laplace_1",
"lm_shrinkage_hs")
models <- map(model_names, function(nm) {
stan_model(file.path("stan", str_c(nm, ".stan")))
})
#> hash mismatch so recompiling; make sure Stan code ends with a blank line
#> In file included from filed8cb12469916.cpp:8:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/src/stan/model/model_header.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core.hpp:14:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core/matrix_vari.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat/fun/Eigen_NumTraits.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat/fun/Eigen.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Dense:1:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Core:531:
#> /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/src/Core/util/ReenableStupidWarnings.h:10:30: warning: pragma diagnostic pop could not pop, no matching push [-Wunknown-pragmas]
#> #pragma clang diagnostic pop
#> ^
#> In file included from filed8cb12469916.cpp:8:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/src/stan/model/model_header.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core.hpp:14:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core/matrix_vari.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat/fun/Eigen_NumTraits.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat/fun/Eigen.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Dense:2:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/LU:47:
#> /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/src/Core/util/ReenableStupidWarnings.h:10:30: warning: pragma diagnostic pop could not pop, no matching push [-Wunknown-pragmas]
#> #pragma clang diagnostic pop
#> ^
#> In file included from filed8cb12469916.cpp:8:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/src/stan/model/model_header.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core.hpp:14:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core/matrix_vari.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat/fun/Eigen_NumTraits.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat/fun/Eigen.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Dense:3:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Cholesky:12:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Jacobi:29:
#> /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/src/Core/util/ReenableStupidWarnings.h:10:30: warning: pragma diagnostic pop could not pop, no matching push [-Wunknown-pragmas]
#> #pragma clang diagnostic pop
#> ^
#> In file included from filed8cb12469916.cpp:8:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/src/stan/model/model_header.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core.hpp:14:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core/matrix_vari.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat/fun/Eigen_NumTraits.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat/fun/Eigen.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Dense:3:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Cholesky:43:
#> /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/src/Core/util/ReenableStupidWarnings.h:10:30: warning: pragma diagnostic pop could not pop, no matching push [-Wunknown-pragmas]
#> #pragma clang diagnostic pop
#> ^
#> In file included from filed8cb12469916.cpp:8:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/src/stan/model/model_header.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core.hpp:14:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core/matrix_vari.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat/fun/Eigen_NumTraits.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat/fun/Eigen.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Dense:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/QR:17:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Householder:27:
#> /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/src/Core/util/ReenableStupidWarnings.h:10:30: warning: pragma diagnostic pop could not pop, no matching push [-Wunknown-pragmas]
#> #pragma clang diagnostic pop
#> ^
#> In file included from filed8cb12469916.cpp:8:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/src/stan/model/model_header.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core.hpp:14:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core/matrix_vari.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat/fun/Eigen_NumTraits.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat/fun/Eigen.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Dense:5:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/SVD:48:
#> /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/src/Core/util/ReenableStupidWarnings.h:10:30: warning: pragma diagnostic pop could not pop, no matching push [-Wunknown-pragmas]
#> #pragma clang diagnostic pop
#> ^
#> In file included from filed8cb12469916.cpp:8:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/src/stan/model/model_header.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core.hpp:14:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core/matrix_vari.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat/fun/Eigen_NumTraits.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat/fun/Eigen.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Dense:6:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Geometry:58:
#> /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/src/Core/util/ReenableStupidWarnings.h:10:30: warning: pragma diagnostic pop could not pop, no matching push [-Wunknown-pragmas]
#> #pragma clang diagnostic pop
#> ^
#> In file included from filed8cb12469916.cpp:8:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/src/stan/model/model_header.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core.hpp:14:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core/matrix_vari.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat/fun/Eigen_NumTraits.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat/fun/Eigen.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Dense:7:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Eigenvalues:58:
#> /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/src/Core/util/ReenableStupidWarnings.h:10:30: warning: pragma diagnostic pop could not pop, no matching push [-Wunknown-pragmas]
#> #pragma clang diagnostic pop
#> ^
#> In file included from filed8cb12469916.cpp:8:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/src/stan/model/model_header.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat.hpp:12:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat.hpp:83:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat/fun/csr_extract_u.hpp:6:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Sparse:26:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/SparseCore:66:
#> /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/src/Core/util/ReenableStupidWarnings.h:10:30: warning: pragma diagnostic pop could not pop, no matching push [-Wunknown-pragmas]
#> #pragma clang diagnostic pop
#> ^
#> In file included from filed8cb12469916.cpp:8:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/src/stan/model/model_header.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat.hpp:12:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat.hpp:83:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat/fun/csr_extract_u.hpp:6:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Sparse:27:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/OrderingMethods:71:
#> /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/src/Core/util/ReenableStupidWarnings.h:10:30: warning: pragma diagnostic pop could not pop, no matching push [-Wunknown-pragmas]
#> #pragma clang diagnostic pop
#> ^
#> In file included from filed8cb12469916.cpp:8:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/src/stan/model/model_header.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat.hpp:12:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat.hpp:83:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat/fun/csr_extract_u.hpp:6:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Sparse:29:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/SparseCholesky:43:
#> /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/src/Core/util/ReenableStupidWarnings.h:10:30: warning: pragma diagnostic pop could not pop, no matching push [-Wunknown-pragmas]
#> #pragma clang diagnostic pop
#> ^
#> In file included from filed8cb12469916.cpp:8:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/src/stan/model/model_header.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat.hpp:12:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat.hpp:83:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat/fun/csr_extract_u.hpp:6:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Sparse:32:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/SparseQR:35:
#> /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/src/Core/util/ReenableStupidWarnings.h:10:30: warning: pragma diagnostic pop could not pop, no matching push [-Wunknown-pragmas]
#> #pragma clang diagnostic pop
#> ^
#> In file included from filed8cb12469916.cpp:8:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/src/stan/model/model_header.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat.hpp:12:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat.hpp:83:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat/fun/csr_extract_u.hpp:6:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Sparse:33:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/IterativeLinearSolvers:46:
#> /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/src/Core/util/ReenableStupidWarnings.h:10:30: warning: pragma diagnostic pop could not pop, no matching push [-Wunknown-pragmas]
#> #pragma clang diagnostic pop
#> ^
#> 13 warnings generated.
#> In file included from filed8cbdf0834b.cpp:8:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/src/stan/model/model_header.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core.hpp:14:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core/matrix_vari.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat/fun/Eigen_NumTraits.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat/fun/Eigen.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Dense:1:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Core:531:
#> /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/src/Core/util/ReenableStupidWarnings.h:10:30: warning: pragma diagnostic pop could not pop, no matching push [-Wunknown-pragmas]
#> #pragma clang diagnostic pop
#> ^
#> In file included from filed8cbdf0834b.cpp:8:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/src/stan/model/model_header.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core.hpp:14:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core/matrix_vari.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat/fun/Eigen_NumTraits.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat/fun/Eigen.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Dense:2:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/LU:47:
#> /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/src/Core/util/ReenableStupidWarnings.h:10:30: warning: pragma diagnostic pop could not pop, no matching push [-Wunknown-pragmas]
#> #pragma clang diagnostic pop
#> ^
#> In file included from filed8cbdf0834b.cpp:8:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/src/stan/model/model_header.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core.hpp:14:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core/matrix_vari.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat/fun/Eigen_NumTraits.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat/fun/Eigen.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Dense:3:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Cholesky:12:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Jacobi:29:
#> /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/src/Core/util/ReenableStupidWarnings.h:10:30: warning: pragma diagnostic pop could not pop, no matching push [-Wunknown-pragmas]
#> #pragma clang diagnostic pop
#> ^
#> In file included from filed8cbdf0834b.cpp:8:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/src/stan/model/model_header.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core.hpp:14:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core/matrix_vari.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat/fun/Eigen_NumTraits.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat/fun/Eigen.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Dense:3:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Cholesky:43:
#> /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/src/Core/util/ReenableStupidWarnings.h:10:30: warning: pragma diagnostic pop could not pop, no matching push [-Wunknown-pragmas]
#> #pragma clang diagnostic pop
#> ^
#> In file included from filed8cbdf0834b.cpp:8:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/src/stan/model/model_header.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core.hpp:14:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core/matrix_vari.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat/fun/Eigen_NumTraits.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat/fun/Eigen.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Dense:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/QR:17:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Householder:27:
#> /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/src/Core/util/ReenableStupidWarnings.h:10:30: warning: pragma diagnostic pop could not pop, no matching push [-Wunknown-pragmas]
#> #pragma clang diagnostic pop
#> ^
#> In file included from filed8cbdf0834b.cpp:8:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/src/stan/model/model_header.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core.hpp:14:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core/matrix_vari.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat/fun/Eigen_NumTraits.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat/fun/Eigen.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Dense:5:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/SVD:48:
#> /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/src/Core/util/ReenableStupidWarnings.h:10:30: warning: pragma diagnostic pop could not pop, no matching push [-Wunknown-pragmas]
#> #pragma clang diagnostic pop
#> ^
#> In file included from filed8cbdf0834b.cpp:8:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/src/stan/model/model_header.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core.hpp:14:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core/matrix_vari.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat/fun/Eigen_NumTraits.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat/fun/Eigen.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Dense:6:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Geometry:58:
#> /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/src/Core/util/ReenableStupidWarnings.h:10:30: warning: pragma diagnostic pop could not pop, no matching push [-Wunknown-pragmas]
#> #pragma clang diagnostic pop
#> ^
#> In file included from filed8cbdf0834b.cpp:8:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/src/stan/model/model_header.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core.hpp:14:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core/matrix_vari.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat/fun/Eigen_NumTraits.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat/fun/Eigen.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Dense:7:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Eigenvalues:58:
#> /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/src/Core/util/ReenableStupidWarnings.h:10:30: warning: pragma diagnostic pop could not pop, no matching push [-Wunknown-pragmas]
#> #pragma clang diagnostic pop
#> ^
#> In file included from filed8cbdf0834b.cpp:8:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/src/stan/model/model_header.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat.hpp:12:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat.hpp:83:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat/fun/csr_extract_u.hpp:6:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Sparse:26:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/SparseCore:66:
#> /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/src/Core/util/ReenableStupidWarnings.h:10:30: warning: pragma diagnostic pop could not pop, no matching push [-Wunknown-pragmas]
#> #pragma clang diagnostic pop
#> ^
#> In file included from filed8cbdf0834b.cpp:8:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/src/stan/model/model_header.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat.hpp:12:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat.hpp:83:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat/fun/csr_extract_u.hpp:6:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Sparse:27:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/OrderingMethods:71:
#> /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/src/Core/util/ReenableStupidWarnings.h:10:30: warning: pragma diagnostic pop could not pop, no matching push [-Wunknown-pragmas]
#> #pragma clang diagnostic pop
#> ^
#> In file included from filed8cbdf0834b.cpp:8:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/src/stan/model/model_header.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat.hpp:12:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat.hpp:83:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat/fun/csr_extract_u.hpp:6:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Sparse:29:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/SparseCholesky:43:
#> /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/src/Core/util/ReenableStupidWarnings.h:10:30: warning: pragma diagnostic pop could not pop, no matching push [-Wunknown-pragmas]
#> #pragma clang diagnostic pop
#> ^
#> In file included from filed8cbdf0834b.cpp:8:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/src/stan/model/model_header.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat.hpp:12:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat.hpp:83:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat/fun/csr_extract_u.hpp:6:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Sparse:32:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/SparseQR:35:
#> /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/src/Core/util/ReenableStupidWarnings.h:10:30: warning: pragma diagnostic pop could not pop, no matching push [-Wunknown-pragmas]
#> #pragma clang diagnostic pop
#> ^
#> In file included from filed8cbdf0834b.cpp:8:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/src/stan/model/model_header.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat.hpp:12:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat.hpp:83:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat/fun/csr_extract_u.hpp:6:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Sparse:33:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/IterativeLinearSolvers:46:
#> /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/src/Core/util/ReenableStupidWarnings.h:10:30: warning: pragma diagnostic pop could not pop, no matching push [-Wunknown-pragmas]
#> #pragma clang diagnostic pop
#> ^
#> 13 warnings generated.
#> hash mismatch so recompiling; make sure Stan code ends with a blank line
#> In file included from filed8cbfb1fc8b.cpp:8:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/src/stan/model/model_header.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core.hpp:14:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core/matrix_vari.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat/fun/Eigen_NumTraits.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat/fun/Eigen.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Dense:1:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Core:531:
#> /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/src/Core/util/ReenableStupidWarnings.h:10:30: warning: pragma diagnostic pop could not pop, no matching push [-Wunknown-pragmas]
#> #pragma clang diagnostic pop
#> ^
#> In file included from filed8cbfb1fc8b.cpp:8:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/src/stan/model/model_header.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core.hpp:14:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core/matrix_vari.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat/fun/Eigen_NumTraits.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat/fun/Eigen.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Dense:2:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/LU:47:
#> /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/src/Core/util/ReenableStupidWarnings.h:10:30: warning: pragma diagnostic pop could not pop, no matching push [-Wunknown-pragmas]
#> #pragma clang diagnostic pop
#> ^
#> In file included from filed8cbfb1fc8b.cpp:8:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/src/stan/model/model_header.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core.hpp:14:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core/matrix_vari.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat/fun/Eigen_NumTraits.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat/fun/Eigen.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Dense:3:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Cholesky:12:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Jacobi:29:
#> /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/src/Core/util/ReenableStupidWarnings.h:10:30: warning: pragma diagnostic pop could not pop, no matching push [-Wunknown-pragmas]
#> #pragma clang diagnostic pop
#> ^
#> In file included from filed8cbfb1fc8b.cpp:8:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/src/stan/model/model_header.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core.hpp:14:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core/matrix_vari.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat/fun/Eigen_NumTraits.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat/fun/Eigen.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Dense:3:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Cholesky:43:
#> /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/src/Core/util/ReenableStupidWarnings.h:10:30: warning: pragma diagnostic pop could not pop, no matching push [-Wunknown-pragmas]
#> #pragma clang diagnostic pop
#> ^
#> In file included from filed8cbfb1fc8b.cpp:8:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/src/stan/model/model_header.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core.hpp:14:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core/matrix_vari.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat/fun/Eigen_NumTraits.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat/fun/Eigen.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Dense:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/QR:17:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Householder:27:
#> /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/src/Core/util/ReenableStupidWarnings.h:10:30: warning: pragma diagnostic pop could not pop, no matching push [-Wunknown-pragmas]
#> #pragma clang diagnostic pop
#> ^
#> In file included from filed8cbfb1fc8b.cpp:8:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/src/stan/model/model_header.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core.hpp:14:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core/matrix_vari.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat/fun/Eigen_NumTraits.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat/fun/Eigen.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Dense:5:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/SVD:48:
#> /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/src/Core/util/ReenableStupidWarnings.h:10:30: warning: pragma diagnostic pop could not pop, no matching push [-Wunknown-pragmas]
#> #pragma clang diagnostic pop
#> ^
#> In file included from filed8cbfb1fc8b.cpp:8:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/src/stan/model/model_header.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core.hpp:14:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core/matrix_vari.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat/fun/Eigen_NumTraits.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat/fun/Eigen.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Dense:6:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Geometry:58:
#> /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/src/Core/util/ReenableStupidWarnings.h:10:30: warning: pragma diagnostic pop could not pop, no matching push [-Wunknown-pragmas]
#> #pragma clang diagnostic pop
#> ^
#> In file included from filed8cbfb1fc8b.cpp:8:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/src/stan/model/model_header.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core.hpp:14:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core/matrix_vari.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat/fun/Eigen_NumTraits.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat/fun/Eigen.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Dense:7:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Eigenvalues:58:
#> /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/src/Core/util/ReenableStupidWarnings.h:10:30: warning: pragma diagnostic pop could not pop, no matching push [-Wunknown-pragmas]
#> #pragma clang diagnostic pop
#> ^
#> In file included from filed8cbfb1fc8b.cpp:8:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/src/stan/model/model_header.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat.hpp:12:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat.hpp:83:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat/fun/csr_extract_u.hpp:6:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Sparse:26:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/SparseCore:66:
#> /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/src/Core/util/ReenableStupidWarnings.h:10:30: warning: pragma diagnostic pop could not pop, no matching push [-Wunknown-pragmas]
#> #pragma clang diagnostic pop
#> ^
#> In file included from filed8cbfb1fc8b.cpp:8:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/src/stan/model/model_header.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat.hpp:12:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat.hpp:83:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat/fun/csr_extract_u.hpp:6:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Sparse:27:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/OrderingMethods:71:
#> /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/src/Core/util/ReenableStupidWarnings.h:10:30: warning: pragma diagnostic pop could not pop, no matching push [-Wunknown-pragmas]
#> #pragma clang diagnostic pop
#> ^
#> In file included from filed8cbfb1fc8b.cpp:8:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/src/stan/model/model_header.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat.hpp:12:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat.hpp:83:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat/fun/csr_extract_u.hpp:6:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Sparse:29:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/SparseCholesky:43:
#> /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/src/Core/util/ReenableStupidWarnings.h:10:30: warning: pragma diagnostic pop could not pop, no matching push [-Wunknown-pragmas]
#> #pragma clang diagnostic pop
#> ^
#> In file included from filed8cbfb1fc8b.cpp:8:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/src/stan/model/model_header.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat.hpp:12:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat.hpp:83:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat/fun/csr_extract_u.hpp:6:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Sparse:32:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/SparseQR:35:
#> /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/src/Core/util/ReenableStupidWarnings.h:10:30: warning: pragma diagnostic pop could not pop, no matching push [-Wunknown-pragmas]
#> #pragma clang diagnostic pop
#> ^
#> In file included from filed8cbfb1fc8b.cpp:8:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/src/stan/model/model_header.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat.hpp:12:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat.hpp:83:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat/fun/csr_extract_u.hpp:6:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Sparse:33:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/IterativeLinearSolvers:46:
#> /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/src/Core/util/ReenableStupidWarnings.h:10:30: warning: pragma diagnostic pop could not pop, no matching push [-Wunknown-pragmas]
#> #pragma clang diagnostic pop
#> ^
#> 13 warnings generated.
#> In file included from filed8cb6808c138.cpp:8:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/src/stan/model/model_header.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core.hpp:14:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core/matrix_vari.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat/fun/Eigen_NumTraits.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat/fun/Eigen.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Dense:1:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Core:531:
#> /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/src/Core/util/ReenableStupidWarnings.h:10:30: warning: pragma diagnostic pop could not pop, no matching push [-Wunknown-pragmas]
#> #pragma clang diagnostic pop
#> ^
#> In file included from filed8cb6808c138.cpp:8:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/src/stan/model/model_header.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core.hpp:14:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core/matrix_vari.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat/fun/Eigen_NumTraits.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat/fun/Eigen.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Dense:2:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/LU:47:
#> /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/src/Core/util/ReenableStupidWarnings.h:10:30: warning: pragma diagnostic pop could not pop, no matching push [-Wunknown-pragmas]
#> #pragma clang diagnostic pop
#> ^
#> In file included from filed8cb6808c138.cpp:8:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/src/stan/model/model_header.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core.hpp:14:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core/matrix_vari.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat/fun/Eigen_NumTraits.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat/fun/Eigen.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Dense:3:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Cholesky:12:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Jacobi:29:
#> /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/src/Core/util/ReenableStupidWarnings.h:10:30: warning: pragma diagnostic pop could not pop, no matching push [-Wunknown-pragmas]
#> #pragma clang diagnostic pop
#> ^
#> In file included from filed8cb6808c138.cpp:8:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/src/stan/model/model_header.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core.hpp:14:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core/matrix_vari.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat/fun/Eigen_NumTraits.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat/fun/Eigen.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Dense:3:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Cholesky:43:
#> /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/src/Core/util/ReenableStupidWarnings.h:10:30: warning: pragma diagnostic pop could not pop, no matching push [-Wunknown-pragmas]
#> #pragma clang diagnostic pop
#> ^
#> In file included from filed8cb6808c138.cpp:8:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/src/stan/model/model_header.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core.hpp:14:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core/matrix_vari.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat/fun/Eigen_NumTraits.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat/fun/Eigen.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Dense:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/QR:17:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Householder:27:
#> /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/src/Core/util/ReenableStupidWarnings.h:10:30: warning: pragma diagnostic pop could not pop, no matching push [-Wunknown-pragmas]
#> #pragma clang diagnostic pop
#> ^
#> In file included from filed8cb6808c138.cpp:8:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/src/stan/model/model_header.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core.hpp:14:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core/matrix_vari.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat/fun/Eigen_NumTraits.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat/fun/Eigen.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Dense:5:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/SVD:48:
#> /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/src/Core/util/ReenableStupidWarnings.h:10:30: warning: pragma diagnostic pop could not pop, no matching push [-Wunknown-pragmas]
#> #pragma clang diagnostic pop
#> ^
#> In file included from filed8cb6808c138.cpp:8:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/src/stan/model/model_header.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core.hpp:14:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core/matrix_vari.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat/fun/Eigen_NumTraits.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat/fun/Eigen.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Dense:6:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Geometry:58:
#> /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/src/Core/util/ReenableStupidWarnings.h:10:30: warning: pragma diagnostic pop could not pop, no matching push [-Wunknown-pragmas]
#> #pragma clang diagnostic pop
#> ^
#> In file included from filed8cb6808c138.cpp:8:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/src/stan/model/model_header.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core.hpp:14:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core/matrix_vari.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat/fun/Eigen_NumTraits.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat/fun/Eigen.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Dense:7:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Eigenvalues:58:
#> /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/src/Core/util/ReenableStupidWarnings.h:10:30: warning: pragma diagnostic pop could not pop, no matching push [-Wunknown-pragmas]
#> #pragma clang diagnostic pop
#> ^
#> In file included from filed8cb6808c138.cpp:8:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/src/stan/model/model_header.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat.hpp:12:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat.hpp:83:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat/fun/csr_extract_u.hpp:6:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Sparse:26:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/SparseCore:66:
#> /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/src/Core/util/ReenableStupidWarnings.h:10:30: warning: pragma diagnostic pop could not pop, no matching push [-Wunknown-pragmas]
#> #pragma clang diagnostic pop
#> ^
#> In file included from filed8cb6808c138.cpp:8:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/src/stan/model/model_header.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat.hpp:12:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat.hpp:83:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat/fun/csr_extract_u.hpp:6:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Sparse:27:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/OrderingMethods:71:
#> /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/src/Core/util/ReenableStupidWarnings.h:10:30: warning: pragma diagnostic pop could not pop, no matching push [-Wunknown-pragmas]
#> #pragma clang diagnostic pop
#> ^
#> In file included from filed8cb6808c138.cpp:8:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/src/stan/model/model_header.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat.hpp:12:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat.hpp:83:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat/fun/csr_extract_u.hpp:6:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Sparse:29:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/SparseCholesky:43:
#> /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/src/Core/util/ReenableStupidWarnings.h:10:30: warning: pragma diagnostic pop could not pop, no matching push [-Wunknown-pragmas]
#> #pragma clang diagnostic pop
#> ^
#> In file included from filed8cb6808c138.cpp:8:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/src/stan/model/model_header.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat.hpp:12:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat.hpp:83:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat/fun/csr_extract_u.hpp:6:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Sparse:32:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/SparseQR:35:
#> /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/src/Core/util/ReenableStupidWarnings.h:10:30: warning: pragma diagnostic pop could not pop, no matching push [-Wunknown-pragmas]
#> #pragma clang diagnostic pop
#> ^
#> In file included from filed8cb6808c138.cpp:8:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/src/stan/model/model_header.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat.hpp:12:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat.hpp:83:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat/fun/csr_extract_u.hpp:6:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Sparse:33:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/IterativeLinearSolvers:46:
#> /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/src/Core/util/ReenableStupidWarnings.h:10:30: warning: pragma diagnostic pop could not pop, no matching push [-Wunknown-pragmas]
#> #pragma clang diagnostic pop
#> ^
#> 13 warnings generated.
#> In file included from filed8cb7e83cc69.cpp:8:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/src/stan/model/model_header.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core.hpp:14:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core/matrix_vari.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat/fun/Eigen_NumTraits.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat/fun/Eigen.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Dense:1:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Core:531:
#> /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/src/Core/util/ReenableStupidWarnings.h:10:30: warning: pragma diagnostic pop could not pop, no matching push [-Wunknown-pragmas]
#> #pragma clang diagnostic pop
#> ^
#> In file included from filed8cb7e83cc69.cpp:8:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/src/stan/model/model_header.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core.hpp:14:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core/matrix_vari.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat/fun/Eigen_NumTraits.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat/fun/Eigen.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Dense:2:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/LU:47:
#> /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/src/Core/util/ReenableStupidWarnings.h:10:30: warning: pragma diagnostic pop could not pop, no matching push [-Wunknown-pragmas]
#> #pragma clang diagnostic pop
#> ^
#> In file included from filed8cb7e83cc69.cpp:8:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/src/stan/model/model_header.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core.hpp:14:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core/matrix_vari.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat/fun/Eigen_NumTraits.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat/fun/Eigen.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Dense:3:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Cholesky:12:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Jacobi:29:
#> /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/src/Core/util/ReenableStupidWarnings.h:10:30: warning: pragma diagnostic pop could not pop, no matching push [-Wunknown-pragmas]
#> #pragma clang diagnostic pop
#> ^
#> In file included from filed8cb7e83cc69.cpp:8:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/src/stan/model/model_header.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core.hpp:14:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core/matrix_vari.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat/fun/Eigen_NumTraits.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat/fun/Eigen.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Dense:3:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Cholesky:43:
#> /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/src/Core/util/ReenableStupidWarnings.h:10:30: warning: pragma diagnostic pop could not pop, no matching push [-Wunknown-pragmas]
#> #pragma clang diagnostic pop
#> ^
#> In file included from filed8cb7e83cc69.cpp:8:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/src/stan/model/model_header.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core.hpp:14:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core/matrix_vari.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat/fun/Eigen_NumTraits.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat/fun/Eigen.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Dense:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/QR:17:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Householder:27:
#> /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/src/Core/util/ReenableStupidWarnings.h:10:30: warning: pragma diagnostic pop could not pop, no matching push [-Wunknown-pragmas]
#> #pragma clang diagnostic pop
#> ^
#> In file included from filed8cb7e83cc69.cpp:8:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/src/stan/model/model_header.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core.hpp:14:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core/matrix_vari.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat/fun/Eigen_NumTraits.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat/fun/Eigen.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Dense:5:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/SVD:48:
#> /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/src/Core/util/ReenableStupidWarnings.h:10:30: warning: pragma diagnostic pop could not pop, no matching push [-Wunknown-pragmas]
#> #pragma clang diagnostic pop
#> ^
#> In file included from filed8cb7e83cc69.cpp:8:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/src/stan/model/model_header.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core.hpp:14:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core/matrix_vari.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat/fun/Eigen_NumTraits.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat/fun/Eigen.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Dense:6:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Geometry:58:
#> /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/src/Core/util/ReenableStupidWarnings.h:10:30: warning: pragma diagnostic pop could not pop, no matching push [-Wunknown-pragmas]
#> #pragma clang diagnostic pop
#> ^
#> In file included from filed8cb7e83cc69.cpp:8:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/src/stan/model/model_header.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core.hpp:14:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/core/matrix_vari.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat/fun/Eigen_NumTraits.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat/fun/Eigen.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Dense:7:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Eigenvalues:58:
#> /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/src/Core/util/ReenableStupidWarnings.h:10:30: warning: pragma diagnostic pop could not pop, no matching push [-Wunknown-pragmas]
#> #pragma clang diagnostic pop
#> ^
#> In file included from filed8cb7e83cc69.cpp:8:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/src/stan/model/model_header.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat.hpp:12:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat.hpp:83:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat/fun/csr_extract_u.hpp:6:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Sparse:26:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/SparseCore:66:
#> /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/src/Core/util/ReenableStupidWarnings.h:10:30: warning: pragma diagnostic pop could not pop, no matching push [-Wunknown-pragmas]
#> #pragma clang diagnostic pop
#> ^
#> In file included from filed8cb7e83cc69.cpp:8:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/src/stan/model/model_header.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat.hpp:12:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat.hpp:83:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat/fun/csr_extract_u.hpp:6:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Sparse:27:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/OrderingMethods:71:
#> /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/src/Core/util/ReenableStupidWarnings.h:10:30: warning: pragma diagnostic pop could not pop, no matching push [-Wunknown-pragmas]
#> #pragma clang diagnostic pop
#> ^
#> In file included from filed8cb7e83cc69.cpp:8:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/src/stan/model/model_header.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat.hpp:12:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat.hpp:83:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat/fun/csr_extract_u.hpp:6:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Sparse:29:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/SparseCholesky:43:
#> /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/src/Core/util/ReenableStupidWarnings.h:10:30: warning: pragma diagnostic pop could not pop, no matching push [-Wunknown-pragmas]
#> #pragma clang diagnostic pop
#> ^
#> In file included from filed8cb7e83cc69.cpp:8:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/src/stan/model/model_header.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat.hpp:12:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat.hpp:83:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat/fun/csr_extract_u.hpp:6:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Sparse:32:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/SparseQR:35:
#> /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/src/Core/util/ReenableStupidWarnings.h:10:30: warning: pragma diagnostic pop could not pop, no matching push [-Wunknown-pragmas]
#> #pragma clang diagnostic pop
#> ^
#> In file included from filed8cb7e83cc69.cpp:8:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/src/stan/model/model_header.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math.hpp:4:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/rev/mat.hpp:12:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat.hpp:83:
#> In file included from /Users/jrnold/Library/R/3.5/library/StanHeaders/include/stan/math/prim/mat/fun/csr_extract_u.hpp:6:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/Sparse:33:
#> In file included from /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/IterativeLinearSolvers:46:
#> /Users/jrnold/Library/R/3.5/library/RcppEigen/include/Eigen/src/Core/util/ReenableStupidWarnings.h:10:30: warning: pragma diagnostic pop could not pop, no matching push [-Wunknown-pragmas]
#> #pragma clang diagnostic pop
#> ^
#> 13 warnings generated.
names(models) <- model_namesThis preprocesses the data that will be used by all the models.
diabetes_standata <- lst(
X = scale(diabetes$x),
K = ncol(X),
N = nrow(X),
y = as.numeric(scale(diabetes$y)),
scale_alpha = 10,
rate_sigma = 1,
use_log_lik = 1,
use_y_rep = 1
)diabetes_standata_winf <- within(diabetes_standata, {
scale_beta <- rep(2.5, K)
})
fit_normal <- sampling(models[["lm_normal_1"]],
data = diabetes_standata_winf)diabetes_standata_normal <- within(diabetes_standata, {
df_tau <- 4
scale_tau <- 2.5
})
fit_normal <- sampling(models[["lm_shrinkage_normal_1"]],
data = diabetes_standata_normal,
control = list(adapt_delta = 0.95))diabetes_standata_student_t <- within(diabetes_standata, {
df_tau <- 4
scale_tau <- 1
df_lambda <- 2
})
fit_student <- sampling(models[["lm_shrinkage_student_t_1"]],
data = diabetes_standata_student_t,
control = list(adapt_delta = 0.99, max_treedepth = 13))
#> Warning: There were 6 divergent transitions after warmup. Increasing adapt_delta above 0.99 may help. See
#> http://mc-stan.org/misc/warnings.html#divergent-transitions-after-warmup
#> Warning: Examine the pairs() plot to diagnose sampling problemsdiabetes_nonzero <- lasso_nonzeros(diabetes_lasso_cv)
diabetes_standata_hs <- within(diabetes_standata, {
scale_tau <- diabetes_nonzero / (K - diabetes_nonzero) / sqrt(N)
df_tau <- 1
df_slab <- 25
scale_slab <- 4
df_lambda <- 1
})
fit_hs <- sampling(models[["lm_shrinkage_hs"]],
data = diabetes_standata_hs,
control = list(adapt_delta = 0.99))
#> Warning: There were 10 divergent transitions after warmup. Increasing adapt_delta above 0.99 may help. See
#> http://mc-stan.org/misc/warnings.html#divergent-transitions-after-warmup
#> Warning: Examine the pairs() plot to diagnose sampling problems19.6.1.2.2 rstanarm
Estimate a model with a weakly informative prior.
fit_diabetes <- list()
fit_diabetes[["weak_inf"]] <- stan_glm(y ~ x,
family = gaussian(),
prior = normal(location = 0, scale = 2.5, autoscale = TRUE),
prior_intercept = normal(location = 0, scale = 10, autoscale = TRUE),
prior_aux = exponential(rate = 1, autoscale = TRUE),
data = diabetes, refresh = -1)Estimate a model using the hierarchical shrinkage prior included in rstanarm.
tau0 <- 4 / (ncol(diabetes$x) - 4) / sqrt(nrow(diabetes$x))
fit_diabetes[["hs"]] <-
stan_glm(y ~ x,
family = gaussian(),
prior = hs(df = 1,
global_df = 1,
global_scale = tau0,
slab_df = 25,
slab_scale = 2.5 * sd(diabetes$y)),
data = diabetes)stan_glmdoes not adjust for the scale of the outcome or covariates in the
slab.
However, if slab_df is set to a low value, such as the default slab_df = 4, the tails of the Student-t distribution are wid enough that the data can overcome the likelihood even if slab_scale is narrow.
If slab_df is set to a higher number, the narrow tails mean that slab_scale must be set to the a reasonable value.
Estimate a model with Laplace priors.
fit_diabetes[["lasso"]] <- stan_glm(y ~ x,
family = gaussian(),
prior = lasso(df = 1, location = 0, scale = 2.5,
autoscale = TRUE),
prior_intercept = normal(location = 0, scale = 10),
prior_aux = exponential(rate = 1, autoscale = TRUE),
data = diabetes)19.6.2 Example
Some fake sparse data[^sparse-fake]
n <- 100
p <- 100 # number of variables
s <- 3 # number of variables with non-zero coefficients
X <- matrix(rnorm(n * p), ncol = p)
beta <- c(rep(5, s), rep(0, p - s))
Y <- X %*% beta + rnorm(n)19.8 Variable Selection
Variable selection is closely related to sparse shrinkage methods. Sparse shrinkage methods can be seen as offering an alternative.
Can sparse shrinkage estimators do variable selection? It depends on the what estimator is being used.
- MAP - posterior mode. Yes, it can se some coefficients to zero.
- Posterior mean. No, it only shrinks them.
Note that the shrinkage/not selection properties of the posterior mean also applied to BMA and the mixture methods. They will assign some probability to both zero and non-zero values of each coefficient values, so the posterior mean will (almost certainly) be non-zero, even if the posterior includes a point mass at zero.
However, we can calculate the posterior distribution and then use a second step to decide on the “sparse” model.
- HPD: select the combination of coefficients with the highest posterior density (BMA, spike-and-slab).
- MPD: select any variables where the median of the probability of inclusion is greater than 0.5 (BMA, spike-and-slab).
- Ad hoc-rule for horseshoe priro: select if \(\kappa_k < 0.5\) (Datta and Ghosh). This is the equivalent of the MPD rule.
- Decision problem: e.g. projpred, and Hahn and Carvalho.